
13/04/2023 (2023-04-13)
[Source : pgibertie.com via openvaet-substack-com]
Par JOSH GUETZKOW
111 disparus rien qu’en Argentine — le sujet #12312982 nous montre pourquoi il est peu probable que ce soit « juste une erreur ».
Introduction
Le logiciel qui a attribué les numéros d’identification des sujets pour l’essai clinique Pfizer/BioNTech génère des numéros d’identification séquentiels, qui sont attribués aux volontaires lorsqu’ils sont sélectionnés pour être inclus dans l’étude. Nous avons trouvé 301 « lacunes » dans les numéros d’identification des sujets (numéros manquants là où il devrait y en avoir un), et dans plus de quelques cas, plusieurs numéros d’identification séquentiels consécutifs sont manquants.
Ci-dessous, nous commençons notre enquête approfondie sur cette anomalie en examinant comment le logiciel supervisant l’essai fonctionnait lorsqu’un nouveau sujet était inscrit (« L’inscription » était l’étape précédant le dépistage, où le sujet était inscrit par le site d’essai, après le rendez-vous de dépistage avait été coordonné par le sous-traitant de Pfizer, ICON).1
Ensuite, nous soulignons pourquoi la compréhension de ce détail insignifiant est importante pour établir un problème des plus préoccupants : les données de nombreux sujets inscrits à l’essai semblent manquer et peuvent avoir été supprimées.
Nous sommes allés en profondeur pour vérifier si l’erreur que nous soulignons était techniquement faisable et si elle pouvait avoir une explication innocente.
Nous devons remercier Christine Cotton2, biostatisticienne et parmi les premières à dénoncer l’essai, pour le temps considérable qu’elle a consacré à passer en revue ces préoccupations avec nous et à nous aider à garantir l’exactitude des données présentées ci-dessous.
Inscription d’un sujet
ICON a « présélectionné » les sujets d’essai potentiels avant qu’ils ne se présentent sur un site d’essai physique3, en saisissant des données de base telles que l’âge, la race, le poids et la taille, etc. Plus tard dans l’essai, des volontaires pourraient également être recrutés sur les sites d’essai.
Lorsqu’un sujet était inscrit, le logiciel ICON (« Firecrest », une interface synchronisée par une base de données centrale alimentée par Oracle4) a attribué à ce sujet un identifiant de sujet unique et, surtout, dans les fichiers. XPT :
- Les 4 premiers chiffres désignaient l’identifiant du site d’essai et étaient toujours les mêmes pour tous les sujets de ce même site. (Dans certains cas, les sujets se sont déplacés entre les sites d’essai au cours de l’étude, de sorte que l’identifiant unique complet du sujet a fourni des informations sur le site « actuel » et « d’origine ».)
- Les 4 derniers chiffres désignaient l’ordre d’enregistrement, commençant à 1001. Le sujet suivant enregistré sur un site d’essai donné était alors numéroté 1002, puis 1003, etc.
Entouré en bleu est « l’identifiant de l’étude » (toujours C4591001), encerclé en vert est l’identifiant du site actuel (ici, 1016). Encerclé en jaune est le site d’enregistrement d’origine. Encerclé en rouge est l’identifiant de sujet supplémentaire pour ce site donné.

Vous pouvez vérifier ce phénomène dans cet « extrait d’une page » d’un export de randomisation soumis à la FDA.5

Des erreurs humaines auraient pu se produire ici et là (par exemple, l’investigateur initiant d’une manière ou d’une autre un nouveau sujet deux fois sur une seule personne en cours de dépistage).
Ces erreurs exceptionnelles pourraient alors être rectifiées, soit par demande directe au « gestionnaire de données » (ICON), soit directement par un chercheur principal sur place, qui aurait probablement eu des « privilèges d’administration de données » suffisants qui lui auraient été délégués par le gestionnaire de données.
Une façon plus courante de traiter de tels problèmes aurait été, sur place, de définir le sujet comme « Échec de l’écran » — bien qu’il existe d’autres raisons pour lesquelles les sujets ont échoué à l’examen. Les fichiers de données XPT au niveau du sujet publiés dans le vidage de données de Pfizer incluent 1 295 sujets marqués comme « échecs d’écran ». Il s’agissait de personnes qui ont finalement échoué au dépistage pour une raison ou une autre, même si la plupart avaient vraisemblablement été présélectionnées par ICON.
Sujets disparus
Lorsque nous examinons tous les sujets inscrits à l’essai Pfizer/BioNTech pour les 3 phases âgés de 12 ans et plus, nous nous attendrions alors à ce que les numéros d’identification des sujets soient séquentiels au sein de chaque site. Ainsi, pour chaque site, les numéros d’identification doivent commencer à 1001 et continuer de manière séquentielle (1002, 1003, 1004… etc.). Il ne devrait pas y avoir de lacunes. Mais il y a ! Il y a 301 identifiants de sujet manquants, en supposant que chaque site a commencé à recruter à 1001 jusqu’au dernier identifiant de sujet enregistré sur le site.
Alors, naturellement, nous devons nous demander pourquoi ces identifiants de sujet sont manquants ? Était-ce en quelque sorte le résultat d’une erreur humaine ou informatique, ou est-ce une indication que ces sujets et leurs données ont été supprimés de l’étude pour une raison quelconque ? Quelques numéros d’identification manquants isolés pourraient être attribués à une erreur humaine ou informatique, mais il n’y a aucune raison pour que cela se produise comme ils le font « par erreur », bien qu’en théorie, cela soit possible et si quelqu’un a un innocent explication nous aimerions l’entendre.
Mais certains aspects de ces numéros manquants nous font suspecter une suppression intentionnelle. Pour commencer, si cela était simplement dû à une erreur, nous nous attendrions à ce que la numérotation des sujets saute un sujet à la fois ici et là. Et cela se produit dans de nombreux cas, mais dans d’autres, les chiffres « sautent » par incréments plus importants.
Pour être plus précis, il y a 202 sauts simples dans les données, 22 fois où deux ID d’affilée ont été ignorés, cinq fois où 3 ont été ignorés, deux fois où 4 ont été ignorés, trois fois où 5 ont été ignorés et une fois chacun où 8 et 9 numéros d’identification consécutifs sont manquants.

Pour donner un sens à ce modèle d’identifiants de sujet ignorés, nous devons croire que :
- Un ordinateur qui se comportait très mal a décidé de sauter soudainement plusieurs numéros ici et là pour faire le décompte tout seul.
- Ou certains êtres humains très mal comportés ont supprimé des données.
Nous croyons que les preuves et la logique pointent vers la deuxième hypothèse, mais nous sommes ouverts à d’autres explications.
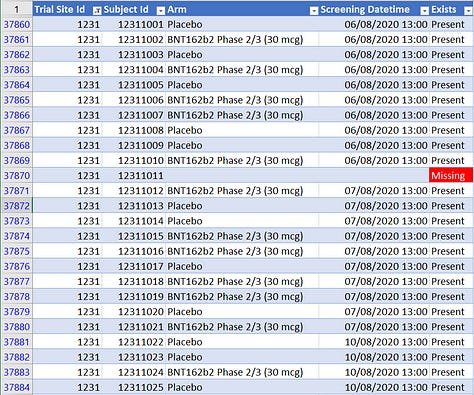
Ces décalages plutôt anormaux sont illustrés dans les captures d’écran ci-dessous. Les plus anormaux se trouvent sur le tristement célèbre site 1231 avec ses site 1231 « données parfaites » (autoproclamées par le chercheur principal).
Comment parfait ? Il y a 111 identifiants de sujets manquants sur le site 1231 (dont 11 sur le pseudo-site 4444). Le site 1231 comptait 5 896 sujets, soit 12,4 % des sujets de l’essai, mais 36,9 % de tous les identifiants de sujets ignorés. Une autre façon de voir les choses est que, si nous ajoutons les identifiants manquants au nombre total de sujets, il manque 1,8 % des identifiants de sujets en Argentine, contre 0,45 % des sites restants. En d’autres termes, le taux de sujets manquants en Argentine est 4 fois supérieur au taux de tous les autres sites réunis. (Évidemment, cette différence est statistiquement très significative.)


Sujets disparus
L’IP du site — Fernando Polack — a fini par devenir l’auteur principal de « l’étude du siècle » du NEJM — le visage public de cette gigantesque fraude — grâce à son degré exceptionnel de compétence médicale en matière de corruption,
Augusto Roux6, participant à ce procès blessé et incendié par Fernando Polack, s’est rendu trop visible pour être « juste réprimé » et a eu le mauvais goût de survivre à ses blessures. Il nous a fourni des informations importantes sur la manière dont les choses étaient (mal) gérées sur le site argentin.7
Pourquoi l’histoire d’Augusto Roux est-elle si importante ici ?
Eh bien, comme on peut le voir dans la capture d’écran du milieu ci-dessus, 17 sujets ont « disparu » en une seule journée, le 21 août 2020. C’est de loin le plus grand nombre d’ID de sujet manquants sur n’importe quel site et n’importe quel jour. C’est aussi le même jour qu’Augusto Roux a été projeté.
Étant donné que presque tous les sujets sur le site d’Argentine ont reçu leur première dose le jour même du dépistage (s’ils ont réussi le dépistage), tous les sujets ayant reçu la première dose ce jour-là auraient été programmés pour recevoir leur deuxième dose trois semaines plus tard, le à la même date qu’Augusto a reçu le sien, ce qui lui a causé un préjudice important — peut-être en raison d’un mauvais lot.
Augusto Roux a survécu et n’a pas été effacé de l’étude. Y en a-t-il eu d’autres, moins chanceux, qui ont été complètement effacés des procès-verbaux ? Ou effacé pour dissimuler un problème ? C’est possible. Et il ne serait pas exagéré de penser que quelque chose a pu mal tourner et affecter 17 sujets le même jour, voire 9 d’affilée. Une autre anomalie majeure s’est produite sur le site argentin deux jours plus tard, le 23 août : 52 sujets ont reçu ce jour-là des doses plus importantes en raison d’une erreur de préparation et ont ensuite été levés en aveugle une semaine plus tard, le 31 août. Dans l’ensemble de données d’écart de protocole8, la raison donnée est « Erreur de dosage/d’administration, le sujet n’a pas reçu la bonne dose de vaccin. » Dans d’autres dossiers, d’autres raisons sont données, mais elles sont toutes liées au produit. Nous savons d’après les dossiers de l’essai que 31 d’entre eux n’ont pas reçu la deuxième dose, et sur les 23 qui l’ont fait, quatre d’entre eux ont eu des événements indésirables importants enregistrés au cours de la période de suivi après la deuxième dose. Nous savons donc qu’il y a eu un problème sur ce site qui a provoqué la levée de l’aveugle de 52 sujets consécutifs, ce qui est une erreur majeure et très anormale. Nous savons également que les effets secondaires d’Augusto Roux ont été étrangement redéfinis (c’est-à-dire masqués).9
À la lumière de tout cela, il est raisonnable d’être méfiant quand on voit cette énorme anomalie de tant de sujets manquants le jour même où Augusto a reçu sa première dose.
Le tableau complet de 48 392 sujets (48 091 identifiants de sujets qui sont restés et les 301 sujets « simplement supprimés ») peut être consulté (trié par site et identifiant de sujet) sur la feuille de calcul Google suivante (avec leurs dates de randomisation et leur bras de traitement, quand disponible).10
Notez qu’il pourrait très bien y avoir plus de sujets qui ont « disparu » (si par exemple le dernier sujet d’un site est 1198, mais que 1199 et 1200 ont été supprimés, nous n’aurions aucun moyen de le savoir à ce stade).
Comment les sujets pourraient-ils être effacés ?
On peut penser à 3 manières dont ces sujets auraient pu être effacés :
- Directement dans la base de données supervisant l’essai
Quelqu’un avec des informations d’identification de base de données (serveur, port, identifiant, mot de passe) pourrait avoir obtenu l’accès, avec ou sans le consentement d’ICON. Avoir un tel accès aurait permis la modification de toutes les données de l’essai (résultats des tests, modification ou effacement des données des sujets, etc.) directement dans la base de données.
- Lors de l’exportation de l’instantané
De la même manière, mais en laissant les « données source brutes inchangées », les exportations de fichiers de données. XPT ou les « instantanés » auraient pu être modifiés, afin de correspondre à un « résultat prédéterminé ». Cela serait plus facile à détecter avec un audit de la « base de données centrale » qu’avec la méthode 1, mais aucun audit de ce type n’a jamais été réalisé à notre connaissance.
- Via une demande du site d’essai au sponsor de l’étude
Vous trouverez ci-dessous une capture d’écran d’une demande (expurgée) adressée à Pfizer pour supprimer un numéro d’identification de sujet provenant d’un site d’essai, qui nous a été fourni par le dénonciateur de Pfizer, Brook Jackson. Ceci est tiré de l’étude de rappel, C4591031. À notre connaissance, cette demande a été acceptée. La raison donnée est : « Le statut SSID a été mis à jour sur SF [Screen Failure], mais aucun sujet n’est associé à ce numéro de sujet. » On ne sait pas comment cela a pu se produire. Il est également possible que ce soit une excuse utilisée pour supprimer un sujet avec des données problématiques. Nous ne savons pas. Nous ne savons pas non plus si le SSID aurait été réutilisé en étant attribué à un autre sujet. Mais ceci est un exemple du type d’erreur qui pourrait produire une poignée de suppressions isolées et uniformément réparties.

- Via le logiciel de gestion
Le chercheur principal sur place aurait pu se voir déléguer des « privilèges élevés » lui permettant de supprimer des symptômes ou des ensembles entiers de données sur le sujet. Si de tels privilèges avaient été accordés par ICON aux employés de Pfizer ou aux PI du site, les seuls endroits où nous pourrions trouver des preuves des modifications seraient les journaux de la base de données et la piste d’audit accessible via le logiciel de gestion. Cela constitue, à notre avis, l’hypothèse la plus probable, surtout au vu du grand nombre de suppressions en Argentine.
Sites d’essai où les sujets ont disparu
La plupart des identifiants de sujet ignorés sont parsemés ici et là individuellement, et seuls 10 sites d’essai en ont plus de 4 :
- 9 sujets au site 1005 avec 442 sujets au total, Rochester Clinical Research, Inc. (Rochester, New York, États-Unis), chercheur principal Matthew Davis.
- 5 sujets au site 1039 avec 334 sujets au total, Arc Clinical Research à Wilson Parke (Austin, Texas, USA), dirigé par Gretchen Crook
- 5 sujets au site 1090 avec 561 sujets au total, M3 Wake Research, Inc (Raleigh, Caroline du Nord, États-Unis), dirigé par Lisa Cohen
- 6 sujets au site 1109 avec 557 sujets au total, DeLand Clinical Research Unit (DeLand, Floride, États-Unis), dirigée par Bruce Rankin
- 6 sujets sur le site 1142 avec 390 sujets au total, University of Texas Medical Branch (Galveston, Texas, USA), dirigé par Richard Rupp
- 5 sujets au site 1146 avec 395 sujets au total, Amici Clinical Research (Rajitan, New York, USA)
- 8 sujets au site 1147 avec 340 sujets au total, Ochsner Clinic Foundation (Nouvelle-Orléans, Louisiane, États-Unis), dirigée par Julia Garcia-Diaz
- 5 sujets au site 1166 avec 107 sujets au total, Rapid Medical Research, Inc. (Cleveland, Ohio, USA), dirigé par Mary Beth Manning
- 5 sujets au site 1170 avec 496 sujets au total, North Texas Infectious Deseases Consultants, PA (Dallas, Texas, USA), dirigé par Mezgebe Berhe
- 111 sujets (100 sujets au site 1231 avec 4585 sujets au total et 11 au site 4444 avec 1311 sujets au total), Hospital Militar Central (Caba, Argentine), dirigé par Fernando Polack (100 subjects
De telles anomalies devraient se produire extrêmement rarement, voire pas du tout. Et, si le problème était dû à une erreur, nous nous attendrions à une répartition assez uniforme ou entre les sites. Mais ici, nous voyons 55 % des suppressions sur 10 sites où seulement 20 % environ de tous les sujets de l’essai étaient inscrits. Et comme nous l’avons vu précédemment, 37 % de tous les sujets supprimés se trouvaient sur un seul site [Argentine] qui n’a recruté que 12 % des sujets de l’essai. La probabilité que de telles suppressions disproportionnées se produisent par hasard est extrêmement faible, bien inférieure à 1 sur un million.
Le code utilisé pour générer cette première analyse est accessible sur GitHub on GitHub..
Mais attendez, il y a plus !
Un document PDF obtenu via FOI [ASK-99541] auprès de l’Agence Européenne du Médicament [EMA], étiqueté « c4591001-interim-mth6-investigators.pdf », et créé par Pfizer à partir d’un extrait daté du 29 mars 2021, propose un autre très intéressant aperçu du recrutement et de la randomisation par siteA PDF11. Un exemple de page est présenté ci-dessous.

Nous avons comparé les sujets dépistés & randomisés, par sites, selon le fichier ADSL [Subject level data12] par rapport à ces « valeurs attendues ». Les résultats sont accessibles dans la feuille de calcul Google suivante).13
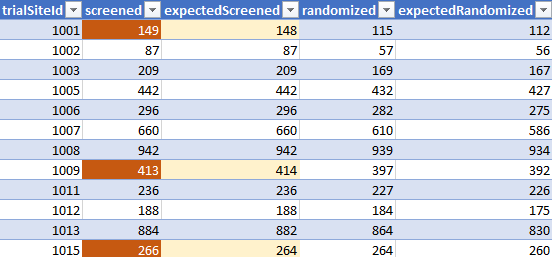
Comme illustré dans le bref échantillon ci-dessus (axé sur les compensations de filtrage), il existe souvent des écarts entre les totaux par site, selon ces données, et les totaux reflétés par le fichier ADSL actuel.
Le total des sujets est très proche (48 092 documentés dans ce PDF vs 48 091 dans le fichier ADSL. Mais peu importe si on teste par site d’origine du sujet [offset de 61]si on teste par site actuel, des différences importantes sont observées entre les sites entre les valeurs de dépistage attendues et observées [par décalages absolus].
Les décalages de randomisation sont encore plus importants, mais secondaires par rapport au problème actuel des « sujets disparus » — et ils seront explorés plus en détail dans un prochain article.
Cela constitue une preuve supplémentaire — à partir des propres extraits des sponsors — que le nombre de sujets a été manipulé.
Le code utilisé pour générer cette dernière analyse est accessible sur GitHub on GitHub..
Ces différents éléments nous conduisent à la conclusion qu’il est urgent que les pistes d’audit — contenant la documentation des opérations d’exportation utilisées pour créer ces fichiers — soient publiées et que des mesures légales soient prises pour sécuriser et enquêter sur les données du serveur de base de données. Nous avons envoyé à la FDA une enquête demandant une explication de ces anomalies et avons reçu une notification indiquant qu’ils allaient l’examiner, mais nous n’avons encore rien entendu. Nous mettrons à jour si nous le faisons.


⚠ Les points de vue exprimés dans l’article ne sont pas nécessairement partagés par les (autres) auteurs et contributeurs du site Nouveau Monde.




















SAVOIR C’EST POUVOIR terrassez »La Bête est là,la Bête arrive j’ai pour mission de détruire ce qu’est la France » »LA DI LA FE » MACRON avec CHARLES III FRANCOIS Bill GATES & Consort F.M Illuminati 60.000 F.M de la firme ont rendez-vous à NUREMBERG II en 2023.@+ sur FACEBOOK:Vivien DURIEUX de CAROLI